Stata Introduction
Topics
- Stata interface and Do-files
- Finding help
- Reading and writing data
- Basic summary statistics
- Basic graphs
- Basic data management
Setup
Software & Materials
Laptop users: you will need a copy of Stata installed on your machine. Harvard FAS affiliates can install a licensed version from http://downloads.fas.harvard.edu/download
- Download class materials at https://github.com/IQSS/dss-workshops/raw/master/Stata/StataIntro.zip
- Extract materials from the zipped directory
StataIntro.zip(Right-click => Extract All on Windows, double-click on Mac) and move them to your desktop!
Organization
- Please feel free to ask questions at any point if they are relevant to the current topic (or if you are lost!)
- Collaboration is encouraged - please introduce yourself to your neighbors!
- If you are using a laptop, you will need to adjust file paths accordingly
- Make comments in your Do-file - save on flash drive or email to yourself
Goals
- This is an introduction to Stata
- Assumes no/very little knowledge of Stata
- Not appropriate for people already familiar with Stata
- Learning Objectives:
- Familiarize yourself with the Stata interface
- Get data in and out of Stata
- Compute statistics and construct graphical displays
- Compute new variables and transformations
Why stata?
- Used in a variety of disciplines
- User-friendly
- Great guides available on web
- Excellent modeling capabilities
- Student and other discount packages available at reasonable cost
Stata interface
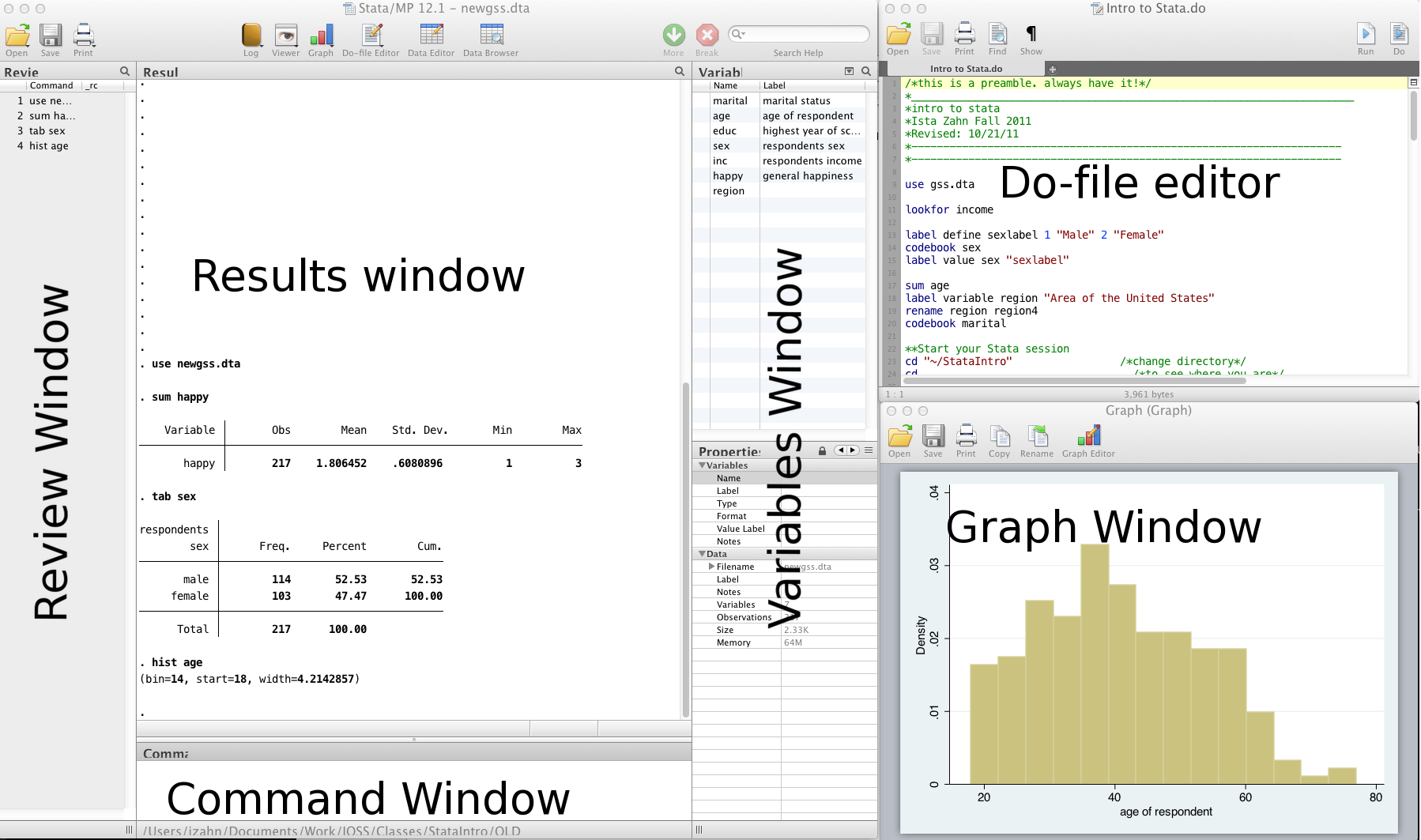
- Review and Variable windows can be closed (user preference)
- Command window can be shortened (recommended)
Do-files
- You can type all the same commands into the Do-file that you would type into the command window
- BUT…the Do-file allows you to save your commands
- Your Do-file should contain ALL commands you executed – at least all the “correct” commands!
- I recommend never using the command window or menus to make CHANGES to data
- Saving commands in Do-file allows you to keep a written record of everything you have done to your data
- Allows easy replication
- Allows you to go back and re-run commands, analyses and make modifications
Stata help
To get help in Stata type help followed by topic or command, e.g., help codebook.
Syntax rules
Most Stata commands follow the same basic syntax: Command varlist, options.
Use comments liberally — start with a comment describing your Do-file and use comments throughout
* Use '*' to comment a line and '//' for in-line comments
* Make Stata say hello:
disp "Hello " "World!" // 'disp' is short for 'display'Use /// to break varlists over multiple lines:
disp "Hello" ///
" World!"Let’s get started
- Launch the Stata program (MP or SE, does not matter unless doing computationally intensive work)
- Open up a new Do-file
- Run our first Stata code!
* change directory
cd "C:/Users/yiw640/Desktop/StataIntro/"Reading data
Data file commands
Next, we want to open our data file Open/save data sets with “use” and “save”:
cd dataSets
// open the gss.dta data set
use gss.dta, clear
// save data file:
save newgss.dta, replace // "replace" option means OK to overwrite existing fileA note about path names
- If your path has no spaces in the name (that means all directories, folders, file names, etc. can have no spaces), you can write the path as it is
- If there are spaces, you need to put your pathname in quotes
- Best to get in the habit of quoting paths
Where’s my data?
- Data editor (browse)
- Data editor (edit)
- Using the data editor is discouraged (why?)
- Always keep any changes to your data in your Do-file
- Avoid temptation of making manual changes by viewing data via the browser rather than editor
Reading non-Stata data
Import delimited text files:
* import data from a .csv file
import delimited gss.csv, clear
* save data to a .csv file
export delimited gss_new.csv, replaceImport data from SAS:
* import/export SAS xport files
import sasxport gss.xpt, clear
export sasxport gss_new, replaceImport data from Excel:
* import/export Excel files
import excel gss.xlsx, clear
export excel gss_new, replaceWhat if my data is from another statistical software program?
- SPSS/PASW will allow you to save your data as a Stata file
- Go to: file -> save as -> Stata (use most recent version available)
- Then you can just go into Stata and open it
- Another option is StatTransfer, a program that converts data from/to many common formats, including SAS, SPSS, Stata, and many more
Exercise 0
Importing data
Save any work you’ve done so far. Close down Stata and open a new session.
Start Stata and open your
.dofile.Change directory (
cd) to thedataSetsfolder.
**- Try opening the following files:
- A comma separated value file:
gss.csv - An Excel file:
gss.xlsx
- A comma separated value file:
**Statistics & graphs
Frequently used commands
- Commands for reviewing and inspecting data:
- describe // labels, storage type etc.
- sum // statistical summary (mean, sd, min/max etc.)
- codebook // storage type, unique values, labels
- list // print actuall values
- tab // (cross) tabulate variables
- browse // view the data in a spreadsheet-like window
First, let’s ask Stata for help about these commands:
help sumuse gss.dta, clear
sum educ // statistical summary of educationcodebook region // information about how region is codedtab sex // numbers of male and female participantsIf you run these commands without specifying variables, Stata will produce output for every variable
Basic graphing commands
// open the gss.dta data set
use gss.dta, clearUnivariate distribution(s) using hist:
/* Histograms */
hist educ // histogram with normal curve; see "help hist" for other options
hist age, normal View bivariate distributions with scatterplots:
/* scatterplots */
twoway (scatter educ age)graph matrix educ age incThe by command
Sometimes, you’d like to generate output based on different categories of a grouping variable The by command does just this:
* By Processing
bysort sex: tab happy // tabulate happy separately for men and womenbysort marital: sum educ // summarize education by marital statusExercise 1
Descriptive statistics
The Generations of Talent Study sought to examine quality of employment as experienced by today’s multigenerational workforces. The primary goal was to explore how country-related factors and age-related factors affect employees’ perceptions of quality of employment. Demographic variables included gender, birth year, race/ethnicity, education, marital * status, number of children, hourly wage, salary, and household income.
- Use the dataset,
talent.dta, open a new do-file and write on the do-file, after the exercise save it to the folder
**- Examine a few selected variables using the describe, sum and codebook commands
**- Tabulate the variable, marital status (
marital), with and without labels
**- Summarize the total household income last year (
income) by marital status
**- Cross-tabulate marital status with respondents’ type of main job (
job)
**- Summarize the total household income last year (
income) for married individuals only
**Basic data management
Labels
- You never know why and when your data may be reviewed
- ALWAYS label every variable no matter how insignificant it may seem
- Stata uses two sets of labels: variable labels and value labels
- Variable labels are very easy to use – value labels are a little more complicated
Variable & value labels
// open the gss.dta data set again
use gss.dta, clearVariable labels
/* Labelling and renaming */
// Label variable inc "household income"
label var inc "household income"
// change the name 'educ' to 'education'
rename educ education
// you can search names and labels with 'lookfor'
lookfor householdValue labels are a two step process: define a value label, then assign defined label to variable(s)
/*define a value label for sex */
label define mySexLabel 1 "Male" 2 "Female"
/* assign our label set to the sex variable*/
label values sex mySexLabel// save the changes
save gss.dta, replace Exercise 2
Variable labels & value labels
- Open the data set
gss.csv
**- Rename and label variables using the following codebook:
**| Var | Rename to | Label with |
|---|---|---|
| v1 | marital | marital status |
| v2 | age | age of respondent |
| v3 | educ | education |
| v4 | sex | respondent’s sex |
| v5 | inc | household income |
| v6 | happy | general happiness |
| v7 | region | region of interview |
- Add value labels to your
maritalvariable using this codebook:
**| Value | Label |
|---|---|
| 1 | “married” |
| 2 | “widowed” |
| 3 | “divorced” |
| 4 | “separated” |
| 5 | “never married” |
Working on subsets
It is often useful to select just those rows of your data where some condition holds–for example select only rows where sex is 1 (male). The following operators allow you to do this:
| Operator | Meaning |
|---|---|
| == | equal to |
| != | not equal to |
| > | greater than |
| >= | greater than or equal to |
| < | less than |
| <= | less than or equal to |
| & | and |
| | | or |
Note the double equals sign == is for testing equality.
Generating & replacing variables
// open the gss.dta data set again
use gss.dta, clearCreate new variables using gen
// create a new variable named mc_inc
// equal to inc minus the mean of inc
gen mc_inc = inc - 15.37 Sometimes useful to start with blank values and fill them in based on values of existing variables
/* the 'generate and replace' strategy */
// generate a column of missings
gen age_wealth = .
// Next, start adding your qualifications
replace age_wealth=1 if age < 30 & inc < 10
replace age_wealth=2 if age < 30 & inc > 10
replace age_wealth=3 if age > 30 & inc < 10
replace age_wealth=4 if age > 30 & inc > 10Exercise 3
Manipulating variables with gen and replace
- Use the dataset,
talent.dta, work on the previous do-file. Save any changes to the data to original data
**- Generate a new “overwork” dummy variable from the original variable
workperweekthat will take on a value of1if a person works more than 40 hours per week, and0if a person works equal to or less than 40 hours per week
**- Generate a new
marital_dummydummy variable from the original variablemaritalthat will take on a value of1if a person is either married or partnered and0otherwise
**- Save the changes to the original dataset
**Use drop to delete variables and keep to keep them
use gss.dta, clear
drop inc
keep age region happy educ sexYou can drop cases selectively using the conditional if, for example:
drop if sex == 2 /*this will drop observations (rows) where gender = 2*/
drop if age > 40 /*this will drop observations where age > 40*/Alternatively, you can keep options you want
keep if sex == 1
keep if age < 40
keep if region == "north" | region == "south"For more details type help keep or help drop.
Exercise 4
Combine all what we have learned together!
- Use the dataset,
talent.dta
**- Rename the
Sexvariable and give it a more intuitive name
**- Use
codebook,describe,tab, andbrowsecommands to know more about how the three variablesA3,A5, andA7are coded and stored, give them new names
**- Plot a histogram distribution for
workperweekand add a normal curve
**- Give a variable label and value labels for the variable
overwork
**- Generate a new variable called
work_familyand code it as2if a respondent perceived work to be more important than family,1if a respondent perceived family to be more important than work, and0if the two are of equal importance
**- Drop the
B3Cvariable that is not used in our exercise
**- Save the changes to a new dataset called
talent_new.dtaand save it to our folder
**Exercise solutions
Ex 0: prototype
clear
cd "C:\Users\yiw640\Desktop\StataIntro\dataSets"
import delimited gss.csv, clear
import excel gss.xlsx, clearEx 1: prototype
use talent.dta, clear
describe workperweek
tab I3
sum income
codebook job
tab marital
tab marital, nol
bysort marital: sum income
tabulate marital job
summarize income if marital == 1Ex 2: prototype
import delimited gss.csv, clear
rename v2 age
rename v3 educ
rename v4 sex
rename v5 inc
rename v6 happy
rename v7 region
label var age "age of respondent"
label var educ "education"
label var sex "respondent's sex"
label var inc "household income"
label var happy "general happiness"
label var region "region of interview"
rename v1 marital
label var marital "marital status"
label define marital_label 1 "married" 2 "widowed" 3 " divorced" 4 "seperated" 5 "never married"
label val marital marital_labelEx 3: prototype
use talent.dta, clear
gen overwork = .
replace overwork = 1 if workperweek > 40
replace overwork = 0 if workperweek <= 40
replace overwork = . if workperweek == .
tab overwork
gen marital_dummy = .
replace marital_dummy = 1 if marital == 1 | marital == 2
replace marital_dummy = 0 if marital != 1 & marital != 2
replace marital_dummy = . if marital == .
tab marital_dummyEx 4: prototype
use talent.dta, clear
rename I3 Sex
codebook A3
describe A5
tab A7
rename A3 otherjob
rename A5 workschedule
rename A7 parttime
hist workperweek, normal
label variable overwork "whether someone works more than 40 hours per week"
label define overworklabel 1 "Yes" 0 "No"
label values overwork overworklabel
gen work_family = .
replace work_family = 2 if B3A > B3B
replace work_family = 1 if B3A < B3B
replace work_family = 0 if B3A == B3B
replace work_family = . if B3A == .
replace work_family = . if B3B == .
drop B3C
save talent_new.dta, replace Wrap-up
Feedback
These workshops are a work in progress, please provide any feedback to: help@iq.harvard.edu
Resources
- IQSS
- Workshops: https://dss.iq.harvard.edu/workshop-materials
- Data Science Services: https://dss.iq.harvard.edu/
- Research Computing Environment: https://iqss.github.io/dss-rce/
- HBS
- Research Computing Services workshops: https://training.rcs.hbs.org/workshops
- Other HBS RCS resources: https://training.rcs.hbs.org/workshop-materials
- RCS consulting email: mailto:research@hbs.edu
- Stata
- UCLA website: http://www.ats.ucla.edu/stat/Stata/
- Stata website: http://www.stata.com/help.cgi?contents
- Email list: http://www.stata.com/statalist/