Python Web-Scraping
Topics
- Web basics
- Making web requests
- Inspecting web sites
- Retrieving web data
- Using Xpaths to retrieve
htmlcontent - Parsing
htmlcontent - Cleaning and storing text from
html
Setup
Class Structure
- Informal — Ask questions at any time. Really!
- Collaboration is encouraged - please spend a minute introducing yourself to your neighbors!
Prerequisites
This is an intermediate / advanced Python course:
- Assumes knowledge of Python, including:
- lists
- dictionaries
- logical indexing
- iteration with for-loops
- Assumes basic knowledge of web page structure
- Relatively fast-paced
If you need an introduction to Python or a refresher, we recommend our Python Introduction.
Goals
This workshop is organized into two main parts:
- Retrive information in JSON format
- Parse HTML files
Note that this workshop will not teach you everything you need to know in order to retrieve data from any web service you might wish to scrape.
Webscraping background
What is web scraping?
Web scraping is the activity of automating retrieval of information from a web service designed for human interaction.
Is web scraping legal? Is it ethical?
It depends. If you have legal questions seek legal counsel. You can mitigate some ethical issues by building delays and restrictions into your web scraping program so as to avoid impacting the availability of the web service for other users or the cost of hosting the service for the service provider.
Web scraping approaches
No two websites are identical — websites are built for different purposes by different people and so have different underlying structures. Because they are heterogeneous, there is no single way to scrape a website. The scraping approach therefore has to be tailored to each individual site. Here are some commonly used approaches:
- Use requests to extract information from structured JSON / XML files
- Use requests to extract information from HTML
- Automate a browser to retrieve information from HTML
Bear in mind that even once you’ve decided upon the best approach for a particular site, it will be necessary to modify that approach to suit your particular use-case.
How does the web work?
Components
Computers connected to the web are called clients and servers. A simplified diagram of how they interact might look like this:
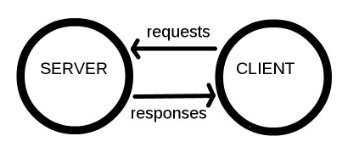
- Clients are the typical web user’s internet-connected devices (for example, your computer connected to your Wi-Fi) and web-accessing software available on those devices (usually a web browser like Firefox or Chrome).
- Servers are computers that store webpages, sites, or apps. When a client device wants to access a webpage, a copy of the webpage is downloaded from the server onto the client machine to be displayed in the user’s web browser.
- HTTP is a language for clients and servers to speak to each other.
So What Happens?
When you type a web address into your browser:
- The browser finds the address of the server that the website lives on.
- The browser sends an HTTP request message to the server, asking it to send a copy of the website to the client.
- If the server approves the client’s request, the server sends the client a “200 OK” message, and then starts displaying the website in the browser.
Retrieve data in JSON format if you can
GOAL: To retrieve information in JSON format and organize it into a spreadsheet.
- Inspect the website to check if the content is stored in JSON format
- Make a request to the website server to retrieve the JSON file
- Convert from JSON format into a Python dictionary
- Extract the data from the dictionary and store in a .csv file
We wish to extract information from https://www.harvardartmuseums.org/collections. Like most modern web pages, a lot goes on behind the scenes to produce the page we see in our browser. Our goal is to pull back the curtain to see what the website does when we interact with it. Once we see how the website works we can start retrieving data from it.
If we are lucky we’ll find a resource that returns the data we’re looking for in a structured format like JSON or XML.
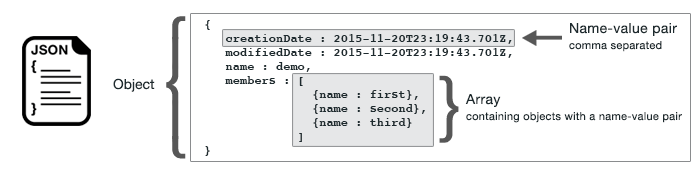
This is useful because it is very easy to convert data from JSON or XML into a spreadsheet type format — like a csv or Excel file.
Examine the website’s structure
The basic strategy is pretty much the same for most scraping projects. We will use our web browser (Chrome or Firefox recommended) to examine the page you wish to retrieve data from, and copy/paste information from your web browser into your scraping program.
We start by opening the collections web page in a web browser and inspecting it.
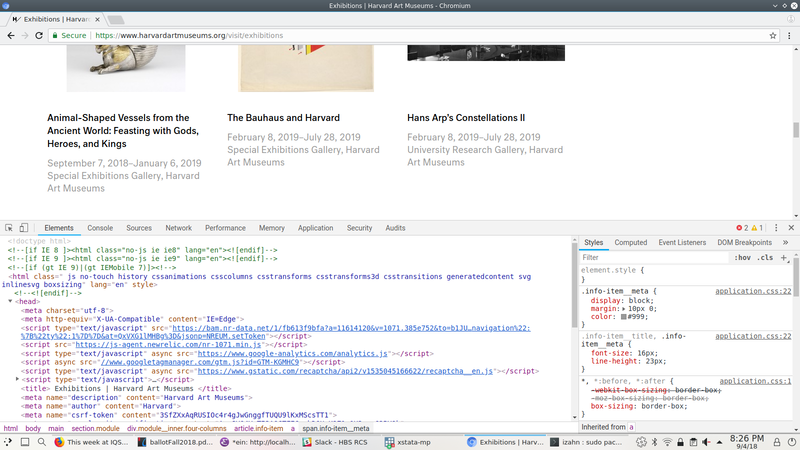
If we scroll down to the bottom of the Collections page, we’ll see a button that says “Load More”. Let’s see what happens when we click on that button. To do so, click on “Network” in the developer tools window, then click the “Load More Collections” button. You should see a list of requests that were made as a result of clicking that button, as shown below.
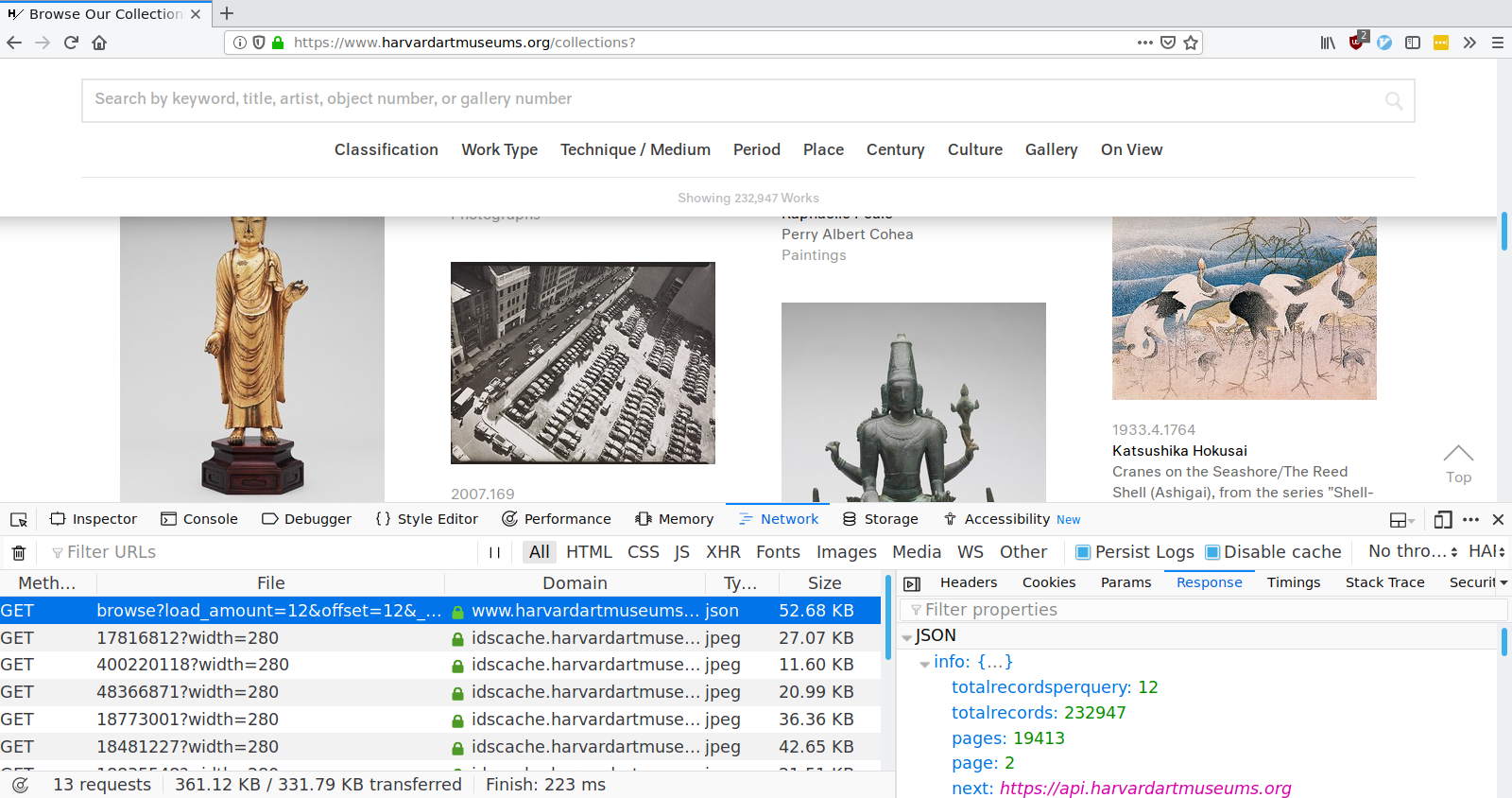
If we look at that second request, the one to a script named browse, we’ll see that it returns all the information we need, in a convenient format called JSON. All we need to retrieve collection data is to make GET requests to https://www.harvardartmuseums.org/browse with the correct parameters.
Launch JupyterLab
- Start the
Anaconda Navigatorprogram - Click the
Launchbutton underJupyter Lab - A browser window will open with your computer’s files listed on the left hand side of the page. Navigate to the folder called
PythonWebScrapethat you downloaded to your desktop and double-click on the folder - Within the
PythonWebScrapefolder, double-click on the file with the word “BLANK” in the name (PythonWebScrape_BLANK.ipynb). A pop-up window will ask you toSelect Kernal— you should select the Python 3 kernal. The Jupyter Notebook should now open on the right hand side of the page
A Jupyter Notebook contains one or more cells containing notes or code. To insert a new cell click the + button in the upper left. To execute a cell, select it and press Control+Enter or click the Run button at the top.
Making requests
To retrieve information from the website (i.e., make a request), we need to know the location of the information we want to collect. The Uniform Resource Locator (URL) — commonly know as a “web address”, specifies the location of a resource (such as a web page) on the internet.
A URL is usually composed of 5 parts:
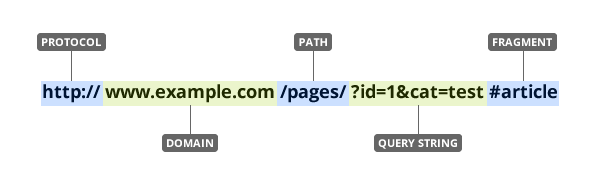
The 4th part, the “query string”, contains one or more parameters. The 5th part, the “fragment”, is an internal page reference and may not be present.
For example, the URL we want to retrieve data from has the following structure:
protocol domain path parameters
https www.harvardartmuseums.org browse load_amount=10&offset=0It is often convenient to create variables containing the domain(s) and path(s) you’ll be working with, as this allows you to swap out paths and parameters as needed. Note that the path is separated from the domain with / and the parameters are separated from the path with ?. If there are multiple parameters they are separated from each other with a &.
For example, we can define the domain and path of the collections URL as follows:
museum_domain = 'https://www.harvardartmuseums.org'
collection_path = 'browse'
collection_url = (museum_domain
+ "/"
+ collection_path)
print(collection_url)## 'https://www.harvardartmuseums.org/browse'Note that we omit the parameters here because it is usually easier to pass them as a dict when using the requests library in Python. This will become clearer shortly.
Now that we’ve constructed the URL we wish to interact with, we’re ready to make our first request in Python.
import requests
collections1 = requests.get(
collection_url,
params = {'load_amount': 10,
'offset': 0}
)Note that the parameters load_amount and offset are essentially another way of setting page numbers — they refer to the amount of information retrieved at one time and the starting position, respectively.
Parsing JSON data
We already know from inspecting network traffic in our web browser that this URL returns JSON, but we can use Python to verify this assumption.
collections1.headers['Content-Type']## 'application/json'Since JSON is a structured data format, parsing it into Python data structures is easy. In fact, there’s a method for that!
collections1 = collections1.json()
# print(collections1)That’s it. Really, we are done here. Everyone go home!
OK not really, there is still more we can learn. But you have to admit that was pretty easy. If you can identify a service that returns the data you want in structured from, web scraping becomes a pretty trivial enterprise. We’ll discuss several other scenarios and topics, but for some web scraping tasks this is really all you need to know.
Organizing & saving the data
The records we retrieved from https://www.harvardartmuseums.org/browse are arranged as a list of dictionaries. We can easily select the fields of arrange these data into a pandas DataFrame to facilitate subsequent analysis.
import pandas as pdrecords1 = pd.DataFrame.from_records(collections1['records'])print(records1)## accessionmethod accessionyear ... verificationleveldescription worktypes
## 0 Purchase 1972 ... Good. Object is well descr... [{'worktypeid': '259', 'wo...
## 1 Gift 2002 ... Good. Object is well descr... [{'worktypeid': '389', 'wo...
## 2 Purchase 2010 ... Good. Object is well descr... [{'worktypeid': '259', 'wo...
## 3 Gift 1895 ... Good. Object is well descr... [{'worktypeid': '389', 'wo...
## 4 Purchase 1991 ... Good. Object is well descr... [{'worktypeid': '342', 'wo...
## 5 Purchase 2000 ... Good. Object is well descr... [{'worktypeid': '278', 'wo...
## 6 Bequest 1940 ... Good. Object is well descr... [{'worktypeid': '278', 'wo...
## 7 Purchase 2008 ... Good. Object is well descr... [{'worktypeid': '259', 'wo...
## 8 Transfer 2011 ... Good. Object is well descr... [{'worktypeid': '259', 'wo...
## 9 Purchase 2007 ... Good. Object is well descr... [{'worktypeid': '369', 'wo...
##
## [10 rows x 61 columns]and write the data to a file.
records1.to_csv("records1.csv")Iterating to retrieve all the data
Of course we don’t want just the first page of collections. How can we retrieve all of them?
Now that we know the web service works, and how to make requests in Python, we can iterate in the usual way.
records = []
for offset in range(0, 50, 10):
param_values = {'load_amount': 10, 'offset': offset}
current_request = requests.get(collection_url, params = param_values)
records += current_request.json()['records']## convert list of dicts to a `DataFrame`
records_final = pd.DataFrame.from_records(records)# write the data to a file.
records_final.to_csv("records_final.csv")print(records_final)## accessionmethod accessionyear ... verificationleveldescription \
## 0 Purchase 1972.0 ... Good. Object is well descr...
## 1 Gift 2002.0 ... Good. Object is well descr...
## 2 Purchase 2010.0 ... Good. Object is well descr...
## 3 Gift 1895.0 ... Good. Object is well descr...
## 4 Purchase 1991.0 ... Good. Object is well descr...
## 5 Purchase 2000.0 ... Good. Object is well descr...
## 6 Bequest 1940.0 ... Good. Object is well descr...
## 7 Purchase 2008.0 ... Good. Object is well descr...
## 8 Transfer 2011.0 ... Good. Object is well descr...
## 9 Purchase 2007.0 ... Good. Object is well descr...
## 10 Purchase 1991.0 ... Good. Object is well descr...
## 11 Gift 1942.0 ... Good. Object is well descr...
## 12 Purchase 2007.0 ... Good. Object is well descr...
## 13 Bequest 1943.0 ... Best. Object is extensivel...
## 14 Gift 2007.0 ... Good. Object is well descr...
## 15 Gift 2001.0 ... Good. Object is well descr...
## 16 Gift 1971.0 ... Best. Object is extensivel...
## 17 Gift 1984.0 ... Adequate. Object is adequa...
## 18 Gift 2007.0 ... Good. Object is well descr...
## 19 Gift 2000.0 ... Good. Object is well descr...
## 20 Purchase 2007.0 ... Good. Object is well descr...
## 21 Transfer 2011.0 ... Good. Object is well descr...
## 22 Bequest 1943.0 ... Adequate. Object is adequa...
## 23 Purchase 1995.0 ... Good. Object is well descr...
## 24 Purchase 1995.0 ... Unchecked. Object informat...
## 25 Purchase 1993.0 ... Good. Object is well descr...
## 26 Purchase 1955.0 ... Good. Object is well descr...
## 27 Bequest 1943.0 ... Best. Object is extensivel...
## 28 Partial Gift/Partial Purchase 2006.0 ... Good. Object is well descr...
## 29 Gift NaN ... Good. Object is well descr...
## 30 Purchase 1986.0 ... Good. Object is well descr...
## 31 None NaN ... Good. Object is well descr...
## 32 Gift 1959.0 ... Good. Object is well descr...
## 33 Purchase 2008.0 ... Good. Object is well descr...
## 34 Purchase 2007.0 ... Good. Object is well descr...
## 35 Purchase 1973.0 ... Good. Object is well descr...
## 36 Gift 1951.0 ... Adequate. Object is adequa...
## 37 Purchase 2008.0 ... Good. Object is well descr...
## 38 Bequest 1943.0 ... Good. Object is well descr...
## 39 Partial Gift/Partial Purchase 2006.0 ... Good. Object is well descr...
## 40 Purchase 2005.0 ... Good. Object is well descr...
## 41 Gift 2003.0 ... Good. Object is well descr...
## 42 Long Term Loan and Promise... 2006.0 ... Good. Object is well descr...
## 43 Bequest 1932.0 ... Best. Object is extensivel...
## 44 Gift 1939.0 ... Best. Object is extensivel...
## 45 Gift 2005.0 ... Good. Object is well descr...
## 46 None NaN ... Good. Object is well descr...
## 47 Purchase 2008.0 ... Good. Object is well descr...
## 48 Purchase 2007.0 ... Good. Object is well descr...
## 49 Purchase 2004.0 ... Best. Object is extensivel...
##
## worktypes
## 0 [{'worktypeid': '259', 'wo...
## 1 [{'worktypeid': '389', 'wo...
## 2 [{'worktypeid': '259', 'wo...
## 3 [{'worktypeid': '389', 'wo...
## 4 [{'worktypeid': '342', 'wo...
## 5 [{'worktypeid': '278', 'wo...
## 6 [{'worktypeid': '278', 'wo...
## 7 [{'worktypeid': '259', 'wo...
## 8 [{'worktypeid': '259', 'wo...
## 9 [{'worktypeid': '369', 'wo...
## 10 [{'worktypeid': '389', 'wo...
## 11 [{'worktypeid': '389', 'wo...
## 12 [{'worktypeid': '259', 'wo...
## 13 [{'worktypeid': '213', 'wo...
## 14 [{'worktypeid': '278', 'wo...
## 15 [{'worktypeid': '225', 'wo...
## 16 [{'worktypeid': '242', 'wo...
## 17 [{'worktypeid': '259', 'wo...
## 18 [{'worktypeid': '259', 'wo...
## 19 [{'worktypeid': '278', 'wo...
## 20 [{'worktypeid': '259', 'wo...
## 21 [{'worktypeid': '259', 'wo...
## 22 [{'worktypeid': '242', 'wo...
## 23 [{'worktypeid': '210', 'wo...
## 24 [{'worktypeid': '208', 'wo...
## 25 [{'worktypeid': '278', 'wo...
## 26 [{'worktypeid': '278', 'wo...
## 27 [{'worktypeid': '125', 'wo...
## 28 [{'worktypeid': '242', 'wo...
## 29 [{'worktypeid': '278', 'wo...
## 30 [{'worktypeid': '278', 'wo...
## 31 [{'worktypeid': '278', 'wo...
## 32 [{'worktypeid': '278', 'wo...
## 33 [{'worktypeid': '389', 'wo...
## 34 [{'worktypeid': '278', 'wo...
## 35 [{'worktypeid': '259', 'wo...
## 36 [{'worktypeid': '138', 'wo...
## 37 [{'worktypeid': '259', 'wo...
## 38 [{'worktypeid': '174', 'wo...
## 39 [{'worktypeid': '389', 'wo...
## 40 [{'worktypeid': '389', 'wo...
## 41 [{'worktypeid': '152', 'wo...
## 42 [{'worktypeid': '317', 'wo...
## 43 [{'worktypeid': '125', 'wo...
## 44 [{'worktypeid': '242', 'wo...
## 45 [{'worktypeid': '278', 'wo...
## 46 [{'worktypeid': '278', 'wo...
## 47 [{'worktypeid': '278', 'wo...
## 48 [{'worktypeid': '125', 'wo...
## 49 [{'worktypeid': '389', 'wo...
##
## [50 rows x 61 columns]Exercise 0
Retrieve exhibits data
In this exercise you will retrieve information about the art exhibitions at Harvard Art Museums from https://www.harvardartmuseums.org/visit/exhibitions
- Using a web browser (Firefox or Chrome recommended) inspect the page at
https://www.harvardartmuseums.org/visit/exhibitions. Examine the network traffic as you interact with the page. Try to find where the data displayed on that page comes from.
##- Make a
getrequest in Python to retrieve the data from the URL identified in step1.
##- Write a loop or list comprehension in Python to retrieve data for the first 5 pages of exhibitions data.
##- Bonus (optional): Convert the data you retrieved into a pandas
DataFrameand save it to a.csvfile.
##Click for Exercise 0 Solution
Question #1:
museum_domain = "https://www.harvardartmuseums.org"
exhibit_path = "search/load_next"
exhibit_url = museum_domain + "/" + exhibit_path
print(exhibit_url)## 'https://www.harvardartmuseums.org/search/load_next'Question #2:
import requests
from pprint import pprint as print
exhibit1 = requests.get(exhibit_url, params = {'type': 'past-exhibition', 'page': 1})
print(exhibit1.headers["Content-Type"])## 'application/json'exhibit1 = exhibit1.json()
# print(exhibit1)Questions #3+4 (loop solution):
firstFivePages = []
for page in range(1, 6):
records_per_page = requests.get(exhibit_url, params = {'type': 'past-exhibition', 'page': page}).json()['records']
firstFivePages.extend(records_per_page)
firstFivePages_records = pd.DataFrame.from_records(firstFivePages)
print(firstFivePages_records)## begindate color ... venues videos
## 0 2018-10-30 None ... [{'ishamvenue': 1, 'galler... NaN
## 1 2018-09-07 None ... [{'ishamvenue': 1, 'galler... NaN
## 2 2018-09-01 None ... [{'ishamvenue': 1, 'galler... NaN
## 3 2018-09-01 None ... [{'ishamvenue': 1, 'galler... NaN
## 4 2018-06-30 None ... [{'ishamvenue': 1, 'galler... [{'primaryurl': 'https://v...
## 5 2018-05-19 None ... [{'ishamvenue': 1, 'galler... NaN
## 6 2018-05-19 None ... [{'ishamvenue': 1, 'galler... NaN
## 7 2018-02-09 None ... [{'ishamvenue': 1, 'galler... NaN
## 8 2018-02-07 None ... [{'ishamvenue': 1, 'galler... NaN
## 9 2018-01-20 None ... [{'ishamvenue': 1, 'galler... NaN
## 10 2018-01-20 None ... [{'ishamvenue': 1, 'galler... [{'primaryurl': 'https://v...
## 11 2018-01-20 None ... [{'ishamvenue': 1, 'galler... NaN
## 12 2017-09-27 None ... [{'ishamvenue': 1, 'galler... NaN
## 13 2017-09-09 None ... [{'ishamvenue': 1, 'galler... NaN
## 14 2017-08-26 None ... [{'ishamvenue': 1, 'galler... NaN
## 15 2017-08-26 None ... [{'ishamvenue': 1, 'galler... NaN
## 16 2017-08-26 None ... [{'ishamvenue': 1, 'galler... NaN
## 17 2017-05-20 None ... [{'ishamvenue': 1, 'galler... [{'primaryurl': 'https://v...
## 18 2017-05-20 None ... [{'ishamvenue': 1, 'galler... NaN
## 19 2017-05-20 None ... [{'ishamvenue': 1, 'galler... NaN
## 20 2017-05-19 None ... [{'ishamvenue': 1, 'galler... [{'primaryurl': 'https://v...
## 21 2017-04-18 None ... [{'ishamvenue': 1, 'galler... NaN
## 22 2017-01-21 None ... [{'ishamvenue': 1, 'galler... NaN
## 23 2016-11-04 None ... [{'ishamvenue': 1, 'galler... NaN
## 24 2016-10-26 None ... [{'ishamvenue': 1, 'galler... NaN
## 25 2016-08-27 None ... [{'ishamvenue': 1, 'galler... NaN
## 26 2016-08-27 None ... [{'ishamvenue': 1, 'galler... NaN
## 27 2016-08-27 None ... [{'ishamvenue': 1, 'galler... [{'primaryurl': 'https://v...
## 28 2016-07-01 None ... [{'ishamvenue': 1, 'galler... NaN
## 29 2016-05-21 None ... [{'ishamvenue': 1, 'galler... NaN
## 30 2016-05-21 None ... [{'ishamvenue': 1, 'galler... NaN
## 31 2016-05-21 None ... [{'ishamvenue': 1, 'galler... NaN
## 32 2016-02-05 None ... [{'ishamvenue': 1, 'galler... NaN
## 33 2016-01-23 None ... [{'ishamvenue': 1, 'galler... NaN
## 34 2016-01-23 None ... [{'ishamvenue': 1, 'galler... NaN
## 35 2016-01-23 None ... [{'ishamvenue': 1, 'galler... NaN
## 36 2016-01-23 None ... [{'ishamvenue': 1, 'galler... NaN
## 37 2015-10-29 None ... [{'ishamvenue': 1, 'galler... NaN
## 38 2015-09-03 #EC5711 ... [{'ishamvenue': 1, 'galler... [{'primaryurl': 'https://v...
## 39 2015-09-03 None ... [{'ishamvenue': 1, 'galler... NaN
## 40 2015-09-03 None ... [{'ishamvenue': 1, 'galler... NaN
## 41 2015-05-23 #657055 ... [{'ishamvenue': 1, 'galler... NaN
## 42 2015-05-23 #999FB6 ... [{'ishamvenue': 1, 'galler... NaN
## 43 2014-11-16 None ... [{'ishamvenue': 1, 'galler... [{'primaryurl': 'https://v...
## 44 2014-11-16 None ... [{'ishamvenue': 1, 'galler... NaN
## 45 2014-11-16 None ... [{'ishamvenue': 1, 'galler... NaN
## 46 2014-11-16 None ... [{'ishamvenue': 1, 'galler... NaN
## 47 2013-01-31 None ... [{'ishamvenue': 1, 'venuei... NaN
## 48 2013-01-31 None ... [{'ishamvenue': 1, 'venuei... NaN
## 49 2013-01-31 None ... [{'ishamvenue': 1, 'venuei... NaN
##
## [50 rows x 19 columns]Questions #3+4 (list comprehension solution):
first5Pages = [requests.get(exhibit_url, params = {'type': 'past-exhibition', 'page': page}).json()['records'] for page in range(1, 6)]
from itertools import chain
first5Pages = list(chain.from_iterable(first5Pages))
import pandas as pd
first5Pages_records = pd.DataFrame.from_records(first5Pages)
print(first5Pages_records)## begindate color ... venues videos
## 0 2018-10-30 None ... [{'ishamvenue': 1, 'galler... NaN
## 1 2018-09-07 None ... [{'ishamvenue': 1, 'galler... NaN
## 2 2018-09-01 None ... [{'ishamvenue': 1, 'galler... NaN
## 3 2018-09-01 None ... [{'ishamvenue': 1, 'galler... NaN
## 4 2018-06-30 None ... [{'ishamvenue': 1, 'galler... [{'primaryurl': 'https://v...
## 5 2018-05-19 None ... [{'ishamvenue': 1, 'galler... NaN
## 6 2018-05-19 None ... [{'ishamvenue': 1, 'galler... NaN
## 7 2018-02-09 None ... [{'ishamvenue': 1, 'galler... NaN
## 8 2018-02-07 None ... [{'ishamvenue': 1, 'galler... NaN
## 9 2018-01-20 None ... [{'ishamvenue': 1, 'galler... NaN
## 10 2018-01-20 None ... [{'ishamvenue': 1, 'galler... [{'primaryurl': 'https://v...
## 11 2018-01-20 None ... [{'ishamvenue': 1, 'galler... NaN
## 12 2017-09-27 None ... [{'ishamvenue': 1, 'galler... NaN
## 13 2017-09-09 None ... [{'ishamvenue': 1, 'galler... NaN
## 14 2017-08-26 None ... [{'ishamvenue': 1, 'galler... NaN
## 15 2017-08-26 None ... [{'ishamvenue': 1, 'galler... NaN
## 16 2017-08-26 None ... [{'ishamvenue': 1, 'galler... NaN
## 17 2017-05-20 None ... [{'ishamvenue': 1, 'galler... [{'primaryurl': 'https://v...
## 18 2017-05-20 None ... [{'ishamvenue': 1, 'galler... NaN
## 19 2017-05-20 None ... [{'ishamvenue': 1, 'galler... NaN
## 20 2017-05-19 None ... [{'ishamvenue': 1, 'galler... [{'primaryurl': 'https://v...
## 21 2017-04-18 None ... [{'ishamvenue': 1, 'galler... NaN
## 22 2017-01-21 None ... [{'ishamvenue': 1, 'galler... NaN
## 23 2016-11-04 None ... [{'ishamvenue': 1, 'galler... NaN
## 24 2016-10-26 None ... [{'ishamvenue': 1, 'galler... NaN
## 25 2016-08-27 None ... [{'ishamvenue': 1, 'galler... NaN
## 26 2016-08-27 None ... [{'ishamvenue': 1, 'galler... NaN
## 27 2016-08-27 None ... [{'ishamvenue': 1, 'galler... [{'primaryurl': 'https://v...
## 28 2016-07-01 None ... [{'ishamvenue': 1, 'galler... NaN
## 29 2016-05-21 None ... [{'ishamvenue': 1, 'galler... NaN
## 30 2016-05-21 None ... [{'ishamvenue': 1, 'galler... NaN
## 31 2016-05-21 None ... [{'ishamvenue': 1, 'galler... NaN
## 32 2016-02-05 None ... [{'ishamvenue': 1, 'galler... NaN
## 33 2016-01-23 None ... [{'ishamvenue': 1, 'galler... NaN
## 34 2016-01-23 None ... [{'ishamvenue': 1, 'galler... NaN
## 35 2016-01-23 None ... [{'ishamvenue': 1, 'galler... NaN
## 36 2016-01-23 None ... [{'ishamvenue': 1, 'galler... NaN
## 37 2015-10-29 None ... [{'ishamvenue': 1, 'galler... NaN
## 38 2015-09-03 #EC5711 ... [{'ishamvenue': 1, 'galler... [{'primaryurl': 'https://v...
## 39 2015-09-03 None ... [{'ishamvenue': 1, 'galler... NaN
## 40 2015-09-03 None ... [{'ishamvenue': 1, 'galler... NaN
## 41 2015-05-23 #657055 ... [{'ishamvenue': 1, 'galler... NaN
## 42 2015-05-23 #999FB6 ... [{'ishamvenue': 1, 'galler... NaN
## 43 2014-11-16 None ... [{'ishamvenue': 1, 'galler... [{'primaryurl': 'https://v...
## 44 2014-11-16 None ... [{'ishamvenue': 1, 'galler... NaN
## 45 2014-11-16 None ... [{'ishamvenue': 1, 'galler... NaN
## 46 2014-11-16 None ... [{'ishamvenue': 1, 'galler... NaN
## 47 2013-01-31 None ... [{'ishamvenue': 1, 'venuei... NaN
## 48 2013-01-31 None ... [{'ishamvenue': 1, 'venuei... NaN
## 49 2013-01-31 None ... [{'ishamvenue': 1, 'venuei... NaN
##
## [50 rows x 19 columns]Parsing HTML if you have to
GOAL: To retrieve information in HTML format and organize it into a spreadsheet.
- Make a request to the website server to retrieve the HTML
- Inspect the HTML to determine the XPATHs that point to the data we want
- Extract the information from the location the XPATHs point to and store in a dictionary
- Convert from a dictionary to a .csv file
As we’ve seen, you can often inspect network traffic or other sources to locate the source of the data you are interested in and the API used to retrieve it. You should always start by looking for these shortcuts and using them where possible. If you are really lucky, you’ll find a shortcut that returns the data as JSON or XML. If you are not quite so lucky, you will have to parse HTML to retrieve the information you need.
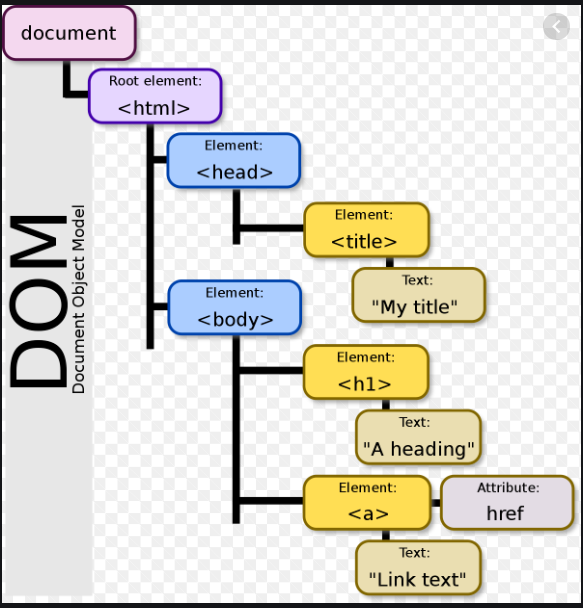
Document Object Model (DOM)
To parse HTML, we need to have a nice tree structure that contains the whole HTML file through which we can locate the information. This tree-like structure is the Document Object Model (DOM). DOM is a cross-platform and language-independent interface that treats an XML or HTML document as a tree structure wherein each node is an object representing a part of the document. The DOM represents a document with a logical tree. Each branch of the tree ends in a node, and each node contains objects. DOM methods allow programmatic access to the tree; with them one can change the structure, style or content of a document. The following is an example of DOM hierarchy in an HTML document:
Retrieving HTML
When I inspected the network traffic while interacting with https://www.harvardartmuseums.org/visit/calendar I didn’t see any requests that returned JSON data. The best we can do appears to be https://www.harvardartmuseums.org/visit/calendar?date=, which unfortunately returns HTML.
The first step is the same as before: we make a GET request.
calendar_path = 'visit/calendar'
calendar_url = (museum_domain # recall that we defined museum_domain earlier
+ "/"
+ calendar_path)
print(calendar_url)## 'https://www.harvardartmuseums.org/visit/calendar'events0 = requests.get(calendar_url, params = {'date': '2018-11'})As before we can check the headers to see what type of content we received in response to our request.
events0.headers['Content-Type']## 'text/html; charset=UTF-8'Parsing HTML using the lxml library
Like JSON, HTML is structured; unlike JSON it is designed to be rendered into a human-readable page rather than simply to store and exchange data in a computer-readable format. Consequently, parsing HTML and extracting information from it is somewhat more difficult than parsing JSON.
While JSON parsing is built into the Python requests library, parsing HTML requires a separate library. I recommend using the HTML parser from the lxml library; others prefer an alternative called beautifulsoup4.
from lxml import html
# convert a html text representation (`events0.text`) into
# a tree-structure (DOM) html representation (`events_html`)
events_html = html.fromstring(events0.text)Using XPath to extract content from HTML
XPath is a tool for identifying particular elements within a HTML document. The developer tools built into modern web browsers make it easy to generate XPaths that can be used to identify the elements of a web page that we wish to extract.
We can open the html document we retrieved and inspect it using our web browser.
html.open_in_browser(events_html, encoding = 'UTF-8')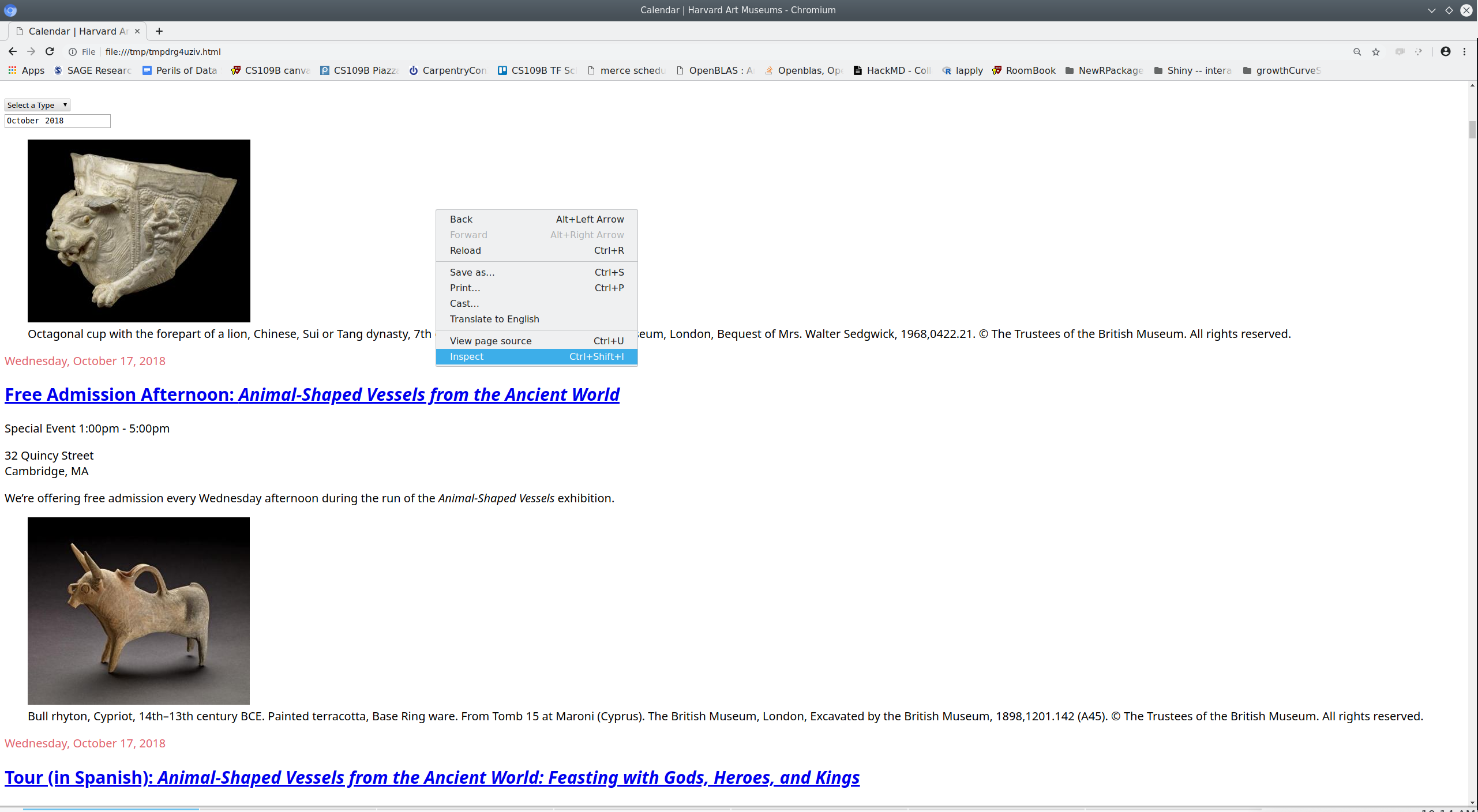
Once we identify the element containing the information of interest we can use our web browser to copy the XPath that uniquely identifies that element.
Next we can use Python to extract the element of interest:
events_list_html = events_html.xpath('//*[@id="events_list"]/article')Once again we can use a web browser to inspect the HTML we’re currently working with, and to figure out what we want to extract from it. Let’s look at the first element in our events list.
first_event_html = events_list_html[0]
html.open_in_browser(first_event_html, encoding = 'UTF-8')As before we can use our browser to find the xpath of the elements we want.
(Note that the html.open_in_browser function adds enclosing html and body tags in order to create a complete web page for viewing. This requires that we adjust the xpath accordingly.)
By repeating this process for each element we want, we can build a list of the xpaths to those elements.
elements_we_want = {'figcaption': 'div/figure/div/figcaption',
'date': 'div/div/header/time',
'title': 'div/div/header/h2/a',
'time': 'div/div/div/p[1]/time',
'localtion1': 'div/div/div/p[2]/span/span[1]',
'location2': 'div/div/div/p[2]/span/span[2]'
}Finally, we can iterate over the elements we want and extract them.
first_event_values = {}
for key in elements_we_want.keys():
element = first_event_html.xpath(elements_we_want[key])[0]
first_event_values[key] = element.text_content().strip()
print(first_event_values)## {'date': 'Wednesday, March 18, 2020',
## 'figcaption': 'Photo: Tim Correira.',
## 'localtion1': '32 Quincy Street',
## 'location2': 'Cambridge',
## 'time': '9:00am - 10:00am',
## 'title': 'Circle of Friends Gallery Tour [CANCELED]'}Iterating to retrieve content from a list of HTML elements
So far we’ve retrieved information only for the first event. To retrieve data for all the events listed on the page we need to iterate over the events. If we are very lucky, each event will have exactly the same information structured in exactly the same way and we can simply extend the code we wrote above to iterate over the events list.
Unfortunately, not all these elements are available for every event, so we need to take care to handle the case where one or more of these elements is not available. We can do that by defining a function that tries to retrieve a value and returns an empty string if it fails.
If you’re not familiar with Python functions, here’s the basic syntax:
# anatomy of a function
def name_of_function(arg1, arg2, ...argn): # define the function name and arguments
<body of function> # specify calculations
return <result> # output result of calculationsHere’s a function to perform our task:
def get_event_info(event, path):
try:
info = event.xpath(path)[0].text.strip()
except:
info = ''
return infoArmed with this function we can iterate over the list of events and extract the available information for each one.
all_event_values = {}
for key in elements_we_want.keys():
key_values = []
for event in events_list_html:
key_values.append(get_event_info(event, elements_we_want[key]))
all_event_values[key] = key_valuesFor convenience we can arrange these values in a pandas DataFrame and save them as .csv files, just as we did with our exhibitions data earlier.
all_event_values = pd.DataFrame.from_dict(all_event_values)
all_event_values.to_csv("all_event_values.csv")
print(all_event_values)## figcaption date ... localtion1 location2
## 0 Photo: Tim Correira. Wednesday, March 18, 2020 ... 32 Quincy Street Cambridge
## 1 Group of Polygnotos, Thursday, March 19, 2020 ... 32 Quincy Street Cambridge
## 2 Tawaraya Sōri, Thursday, March 19, 2020 ... 32 Quincy Street Cambridge
## 3 Maruyama Ōkyo, Tuesday, March 24, 2020 ... 32 Quincy Street Cambridge
## 4 László Moholy-Nagy, Wednesday, March 25, 2020 ... 32 Quincy Street Cambridge
## 5 1958 D. A. Flentrop organ,... Thursday, March 26, 2020 ... 29 Kirkland Street Cambridge
## 6 Mark Bradford, American, Thursday, March 26, 2020 ... 32 Quincy Street Cambridge
## 7 Manufactured by Wedgwood, ... Friday, March 27, 2020 ... 32 Quincy Street Cambridge
## 8 Close-up of a glass muller... Saturday, March 28, 2020 ... 32 Quincy Street Cambridge
## 9 Maruyama Ōkyo, Tuesday, March 31, 2020 ... 32 Quincy Street Cambridge
## 10 Professor Kurt Wehlte in 1... Wednesday, April 1, 2020 ... 32 Quincy Street Cambridge
## 11 1958 D. A. Flentrop organ,... Thursday, April 2, 2020 ... 29 Kirkland Street Cambridge
## 12 Modern forgery of an ancie... Friday, April 3, 2020 ... 32 Quincy Street Cambridge
## 13 Maruyama Ōkyo, Saturday, April 4, 2020 ... 32 Quincy Street Cambridge
## 14 1958 D. A. Flentrop organ,... Thursday, April 9, 2020 ... 29 Kirkland Street Cambridge
## 15 Courtesy of Blue Flower Ar... Thursday, April 9, 2020 ... 32 Quincy Street Cambridge
## 16 Photo: Tim Correira. Wednesday, April 15, 2020 ... 32 Quincy Street Cambridge
## 17 Maruyama Ōkyo, Wednesday, April 15, 2020 ... 32 Quincy Street Cambridge
## 18 1958 D. A. Flentrop organ,... Thursday, April 16, 2020 ... 29 Kirkland Street Cambridge
## 19 Louise Bourgeois, American, Thursday, April 16, 2020 ... 32 Quincy Street Cambridge
## 20 Claude Monet, French, Friday, April 17, 2020 ... 32 Quincy Street Cambridge
## 21 Maruyama Ōkyo, Tuesday, April 21, 2020 ... 32 Quincy Street Cambridge
## 22 Close-up of a glass muller... Tuesday, April 21, 2020 ... 32 Quincy Street Cambridge
## 23 1958 D. A. Flentrop organ,... Thursday, April 23, 2020 ... 29 Kirkland Street Cambridge
## 24 László Moholy-Nagy, Thursday, April 23, 2020 ... 32 Quincy Street Cambridge
## 25 Maruyama Ōkyo, Tuesday, April 28, 2020 ... 32 Quincy Street Cambridge
## 26 Lee Lozano, American, Thursday, April 30, 2020 ... 32 Quincy Street Cambridge
## 27 Friday, May 1, 2020 ... 32 Quincy Street Cambridge
## 28 Maruyama Ōkyo, Wednesday, May 6, 2020 ... 32 Quincy Street Cambridge
## 29 Maruyama Ōkyo, Saturday, May 9, 2020 ... 32 Quincy Street Cambridge
## 30 Charles-Marie Dulac, French, Wednesday, May 13, 2020 ... 32 Quincy Street Cambridge
## 31 Dorothea Lange, American, Tuesday, May 19, 2020 ... 32 Quincy Street Cambridge
## 32 Close-up of a glass muller... Tuesday, May 19, 2020 ... 32 Quincy Street Cambridge
## 33 Photo: Tim Correira. Wednesday, May 20, 2020 ... 32 Quincy Street Cambridge
## 34 Jost Amman, Swiss, Thursday, May 21, 2020 ... 32 Quincy Street Cambridge
## 35 Monday, May 25, 2020 ... 32 Quincy Street Cambridge
## 36 Maruyama Ōkyo, Tuesday, May 26, 2020 ... 32 Quincy Street Cambridge
## 37 © Susan Young Wednesday, May 27, 2020 ... 32 Quincy Street Cambridge
## 38 Lewis W. Rubenstein, Ameri... Wednesday, May 27, 2020 ... 32 Quincy Street Cambridge
## 39 Thursday, May 28, 2020 ... 32 Quincy Street Cambridge
## 40 László Moholy-Nagy, Thursday, May 28, 2020 ... 32 Quincy Street Cambridge
## 41 Photo: Tim Correira. Wednesday, June 17, 2020 ... 32 Quincy Street Cambridge
##
## [42 rows x 6 columns]Exercise 1
parsing HTML
In this exercise you will retrieve information about the physical layout of the Harvard Art Museums. The web page at https://www.harvardartmuseums.org/visit/floor-plan contains this information in HTML from.
Using a web browser (Firefox or Chrome recommended) inspect the page at
https://www.harvardartmuseums.org/visit/floor-plan. Copy theXPathto the element containing the list of level information. (HINT: the element if interest is aul, i.e.,unordered list.)Make a
getrequest in Python to retrieve the web page at https://www.harvardartmuseums.org/visit/floor-plan. Extract the content from your request object and parse it usinghtml.fromstringfrom thelxmllibrary.
##- Use your web browser to find the
XPaths to the facilities housed on level one. Use Python to extract the text from thoseXpaths.
##- Bonus (optional): Write a for loop or list comprehension in Python to retrieve data for all the levels.
##Click for Exercise 1 Solution
Question #2:
from lxml import html
floor_plan = requests.get('https://www.harvardartmuseums.org/visit/floor-plan')
floor_plan_html = html.fromstring(floor_plan.text)Question #3:
level_one = floor_plan_html.xpath('/html/body/main/section/ul/li[5]/div[2]/ul')[0]
print(type(level_one))## <class 'lxml.html.HtmlElement'>print(len(level_one))## 6level_one_facilities = floor_plan_html.xpath('/html/body/main/section/ul/li[5]/div[2]/ul/li')
print(len(level_one_facilities))## 6print([facility.text_content() for facility in level_one_facilities])## ['Admissions', 'Collection Galleries', 'Courtyard', 'Shop', 'Café', 'Coatroom']Question #4:
all_levels = floor_plan_html.xpath('/html/body/main/section/ul/li')
print(len(all_levels))## 6all_levels_facilities = []
for level in all_levels:
level_facilities = []
level_facilities_collection = level.xpath('div[2]/ul/li')
for level_facility in level_facilities_collection:
level_facilities.append(level_facility.text_content())
all_levels_facilities.append(level_facilities)
print(all_levels_facilities)## [['Conservation Center / Lightbox Gallery'],
## ['Art Study Center'],
## ['Collection Galleries',
## 'Special Exhibitions Gallery',
## 'University Galleries'],
## ['Collections Galleries'],
## ['Admissions',
## 'Collection Galleries',
## 'Courtyard',
## 'Shop',
## 'Café',
## 'Coatroom'],
## ['Lower Lobby',
## 'Lecture Halls',
## 'Seminar Room',
## 'Materials Lab',
## 'Coatroom',
## 'Offices']]Scrapy: for large / complex projects
Scraping websites using the requests library to make GET and POST requests, and the lxml library to process HTML is a good way to learn basic web scraping techniques. It is a good choice for small to medium size projects. For very large or complicated scraping tasks the scrapy library offers a number of conveniences, including asynchronous retrieval, session management, convenient methods for extracting and storing values, and more. More information about scrapy can be found at https://doc.scrapy.org.
Browser drivers: a last resort
It is sometimes necessary (or sometimes just easier) to use a web browser as an intermediary rather than communicate directly with a web service. This method of using a “browser driver” has the advantage of being able to use the javascript engine and session management features of a web browser; the main disadvantage is that it is slower and tends to be more fragile than using requests or scrapy to make requests directly from Python. For small scraping projects involving complicated sites with CAPTHAs or lots of complicated javascript using a browser driver can be a good option. More information is available at https://www.seleniumhq.org/docs/03_webdriver.jsp.
Wrap-up
Feedback
These workshops are a work in progress, please provide any feedback to: help@iq.harvard.edu
Resources
- IQSS
- Workshops: https://dss.iq.harvard.edu/workshop-materials
- Data Science Services: https://dss.iq.harvard.edu/
- Research Computing Environment: https://iqss.github.io/dss-rce/
- HBS
- Research Computing Services workshops: https://training.rcs.hbs.org/workshops
- Other HBS RCS resources: https://training.rcs.hbs.org/workshop-materials
- RCS consulting email: mailto:research@hbs.edu